Traceability recovery – where is the evidence?
There are hundreds of papers on trace(ability) recovery, claiming that information retrieval could help engineers. Still, I don’t know any practitioner that has heard about it. Is it a promising software engineering technique or a purely academic construct? This systematic mapping tries to answer this by collecting the empirical evidence.
How do you start PhD studies in software engineering? If you started in the 2010s a safe bet would be a systematic literature review, at least if you were part of an empirical research group. The same applied to me. The overall goal of my funding project was to bring requirements engineering and testing closer, and my part in this was to explore was information retrieval (IR) based traceability recovery – especially traceability between requirements and test cases.
So, what is traceability recovery? Actually it should now be referred to as trace recovery, according to definition in a textbook authored by the most prominent traceability researchers. The idea is quite simple: when you develop a software system it is no (big) problem to maintain traces from the requirements to the design and code in the beginning. But as the systems evolve, a considerable amount of traces are lost. Trace recovery is then the approach to find those lost traces again, pretty much generating a traceability matrix in a messy project. Using IR to do this means finding textually similar artifacts – if two artifacts are really similar, you assume the relation should be captured and represented by a trace.
Rigor all the way – Validating also the search string
I worked on the systematic mapping of IR-based traceability recovery for two years – and there were plenty of papers to find. I’m quite proud of the methodological rigor followed in the study, I really think our work is a good example of how to conduct a literature study. In particular, I like our approach to developing the search string. We first read a lot of papers on the topic to established a “gold set” of publications. Then we evolved a search string that captured as many of them as possible – we did this by actually running queries in the major digital libraries. We followed Kitchenham’s guidelines regarding inclusion/exclusion criteria and data extraction with validation in every step. We even used the tool REVIS to enable a visual validation of our search results. All in all a really mature literature study.
Although we limited the work to studies reporting empirical results, we found as many as 79 publications from a decade of research – starting with Antoniol et al.’s pioneering work from 1999. Actually a very long decade as we cover papers until 2011, but still. For sure a lot of PhD students contributed to this body of knowledge. We took a dive down the papers looking for: 1) What IR models had been used?, 2) What artifacts were linked, and 3) How strong is the evidence that it works?
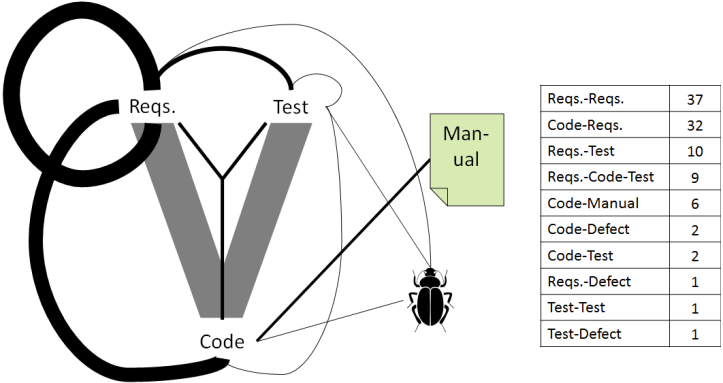
The figure on top of this post shows the relative frequency of “artifact pairs” targeted by previous work. We found that using IR-based tracing to identify links between requirements and between requirements and source code dominated (note that we excluded links within source code). There were some studies looking at requirements-test links, but not as many. Thus we had an opening for future work – suitable for me as a new PhD student!
Algebraic IR models dominate – VSM and LSI most popular
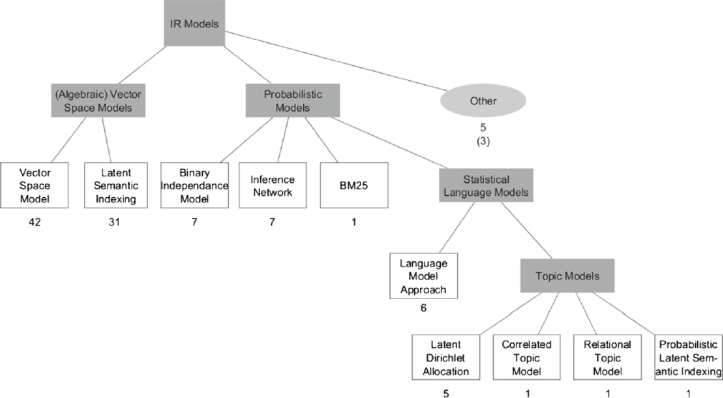
The second research question dealt with IR techniques. We actually drilled down quite deep in the technical matters. For example, I think the background section provides a nice overview of IR from a software engineering perspective. We present a structured overview of IR models used in traceability research, and show that algebraic models (VSM and LSI) had been used the most. However, we also identified the increasing trend of studies using statistical language models such as topic modeling. Nothing surprising found here, but it was nice to quantify the previous work.
many toy examples – Evaluations in industry missing
The final question was pretty much: so does any of this IR-based tracing actually work? Is there any empirical evidence? This is where the paper got really interesting. In the first manuscript first submitted to EMSE, we aggregated results from previous studies comparing different IR models on the same data. Thus we could find general trends of which models are the most promising – but we found no conclusive patterns! That part of the paper wasn’t accepted by the reviewers, who complained about apples and pears (true, but still ok if done properly – later got accepted as a short paper at the ESEM conference).

We instead focused on the industrial relevance of the previous empirical studies, reporting two main findings. First, a lot of previous work studied really small datasets – toy examples – most often fewer than 500 software artifacts. Second, far too many previous studies are really simplistic and only report quantitative results from similarity calculations compared to a “ground truth” set of traces. What about studies with users? We actually identified a subset of studies using Italian students as subjects – surely a step in the right direction, but not at all comparable to the complexity of projects practitioners face in industry. Our study found only one industrial case study trying out IR-based trace recovery, a small pilot from a Chinese company. We could only conclude that there was no compelling evidence supporting the usefulness of IR-based trace recovery, and stress the importance of more evaluations in industry.
Another thing I like about this paper is that we published all included papers, including all data used to draw our conclusions, in a spreadsheet on a public website: TraceRepo. The information includes the data extracted from the papers, and how we classified the information according to some 15 dimensions. We encouraged the community to discuss the spreadsheet and ask for editing rights, but that never took off. I still like the idea though, it feels like an example of open science!
Implications for RESEARCH
- There is an alarming lack of industrial case studies. Numerous papers, but the community needs to show that IR-based trace recovery is more than hot air.
- Purely quantitative studies can still bring value, but stop experimenting with toy data.
- The systematic mapping is a useful foundation for future work in the field, both considering technology and empirical evidence.
Implications for Practice
- There is limited evidence supporting the utility of IR-based trace recovery in an industrial context.
- More empirical research is needed. Please grant researchers access to your data to enable relevant studies.
Markus Borg, Per Runeson, and Anders Ardö. Recovering from a Decade: A Systematic Mapping of Information Retrieval Approaches to Software Traceability, Empirical Software Engineering, 19(6), pp. 1565-1616, 2014. (link, preprint, data)
Abstract
Engineers in large-scale software development have to manage large amounts of information, spread across many artifacts. Several researchers have proposed expressing retrieval of trace links among artifacts, i.e. trace recovery, as an Information Retrieval (IR) problem. The objective of this study is to produce a map of work on IR-based trace recovery, with a particular focus on previous evaluations and strength of evidence. We conducted a systematic mapping of IR-based trace recovery. Of the 79 publications classified, a majority applied algebraic IR models. While a set of studies on students indicate that IR-based trace recovery tools support certain work tasks, most previous studies do not go beyond reporting precision and recall of candidate trace links from evaluations using datasets containing less than 500 artifacts. Our review identified a need of industrial case studies. Furthermore, we conclude that the overall quality of reporting should be improved regarding both context and tool details, measures reported, and use of IR terminology. Finally, based on our empirical findings, we present suggestions on how to advance research on IR-based trace recovery.


